Foundation models for vision

This image was used in Andrej Karpathy’s blog in 2012 to highlight the challenges for a vision-based foundation model (VFM). To accurately understand this picture, the model has to go beyond making disconnected predictions of certain objects (such as human faces), and make sense of the interactions between those objects, spatial relationships, perform visual reasoning along with being able to ingest multimodal data. Fast forward to 2023, and we have made tremendous progress in terms of solving these problems, in large part driven by the emergence of foundation models. Indeed, it is reported that GPT-4V is able to reason about and describe the humor in this image. Assuming that this image was not in the training set, what are the implications for the state of ML in vision? What if we ask this model to perform tasks that seem more uncommon compared to the ones covered by common benchmarks - segment out only those people who are not smiling, or count the squares in the floor that are covered by shadows?
Capabilities of a VFM
In this post, we will discuss ideas and themes in terms of building foundation models for vision, along with selected methods that implement them. We will start by discussion some ideal capabilities that we might expect from a VFM -
- Segmenting stuff/things of interest - A fundamental task in vision to segment out relevant areas in an image. These can include either stuff (amorphous regions like sky) or things (person, car etc). An accurate segmentation mask is precursor to tasks such as detection and classification and can produce outputs of the other such tasks. Segmentation masks also let one compute morphological features of objects, which can be very important for applications such as medical imaging.
- Recognizing stuff/things of interest - While accurate segmentation is a useful first step, we often need to go beyond that and assign labels to the segmented objects/regions.
- Ingesting open vocabulary - Text can encode complex information that is not possible to convey via images.This is helpful since the segmentation task is an underspecified task. For example, in the image above, instead of segmenting people or faces, we might want to segment something more specific, such as persons whose reflections appear in the mirror. This information can be easily conveyed via text, which means our foundation model should be able to ingest and understand this information. There can be other complex instructions around spatial understanding that can be shared to the model via text, which the model should be able to parse and use to generate required outputs. Training via language has another big advantage - it enables these models to predict classes which are not predefined at the time of training (hence the name “open-set”).
- Compositional understanding - Compositionality is a fundamental ingredient for understanding. If the words in a caption are permuted (“weighing machine standing on man” vs “man standing on weighing machine” in our image) would the model’s segmented masks reflect that change? Benchmarks such as Winoground and ARO(Attribute, Relation and Order) test whether Vision-Language models behave like a Bag of Words model. This lack of compositional understanding can be a critical factor against deploying these models in certain applications such as medical imaging. For instance, determining spatial relationships may be context-based as “immune cells surrounded by cancer cells” has a very different meaning than “cancer cells surrounded by immune cells”.
- Calibration - The model should output a measure of its prediction uncertainty which should be well calibrated, so that its can avoid confidently providing a wrong answer whenever it is unsure about the task at hand.
- In-context learning - Novel concepts and semantic structures that are unseen by the model at training time are always a possibility. In such cases, the model should have the ability to infer while taking into account the in-context examples or ‘prompts’, without needing to go into resource-intensive model development cycles.
Next, we will discuss some approaches for solving these challenges -
Universal Segmenter
Segment Anything (SAM) is a popular approach for this class of models. The components are - a heavyweight image encoder (ViT-H gives best results in SAM) that will extract features from image as a one-time operation, and a lightweight encoder that can accept different types of inputs as prompts. The interaction between the image and prompt encodings is covered via cross attention in the mask decoder. The idea is that the image features are already rich enough to contain information about all downstream tasks. The prompt tokens serve to focus on specific regions of the image. The original prompt tokens are re-added to updated tokens after every attention operation. However, the ablations around this operation and other steps that add complexity to the mask decoder are not shared. The training recipe is the key reason behind SAM’s performance on interactive segmentation - this interaction is simulated at the time of training itself! Specifically, once the model predicts a mask, a set of points from the error regions serve as pseudo user generated corrections for False Negatives and Positives. Next, the position encoding + learned foreground-background embeddings for these points along with the previously generated mask logits are passed to the model. SAM can also be used with text embeddings from a vision-language model like CLIP as prompts, although this version hasn’t been released open-source.
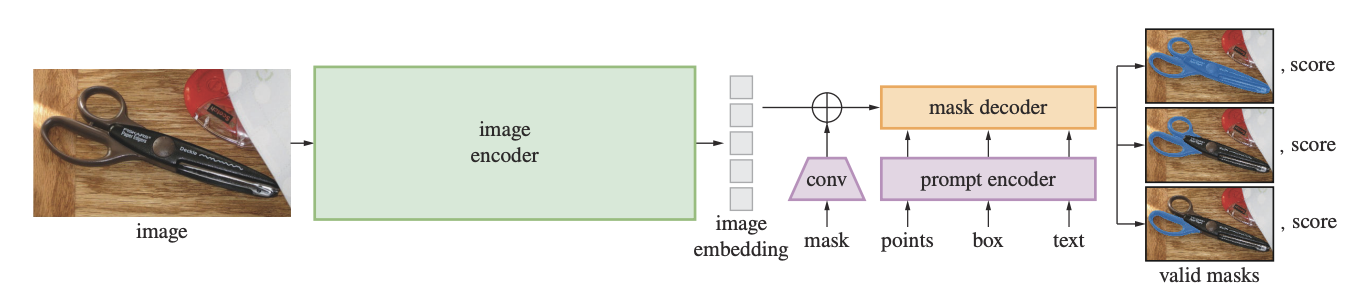
Segment Anything Model enables generation of zero-shot segmentation masks for an image
Vision Language Models and Grounding
Vision Language Models (VLMs), as the name implies, can ingest both language and images. A famous example is CLIP, where contrastive learning is applied on text and image embeddings. The embeddings trained through this approach are more robust to adversarial datasets and settings not commonly used in standard vision benchmarks, such as ImageNet Sketch, ObjectNet etc. However, fine-grained understanding of images and text order awareness might not be prioritized in simple contrastive learning. One approach to mitigate this is via composition-aware hard negative mining. Another line of work (GLIP, Grounding DINO) involves “phrase grounding” - grounding regions in the image to the corresponding phrases in the caption which leads to better localization. Additionally, in these methods, deep cross-modality fusion is performed instead of late fusion. These models are better at detecting rare categories and phrases with attributes which can be important in certain real world applications.
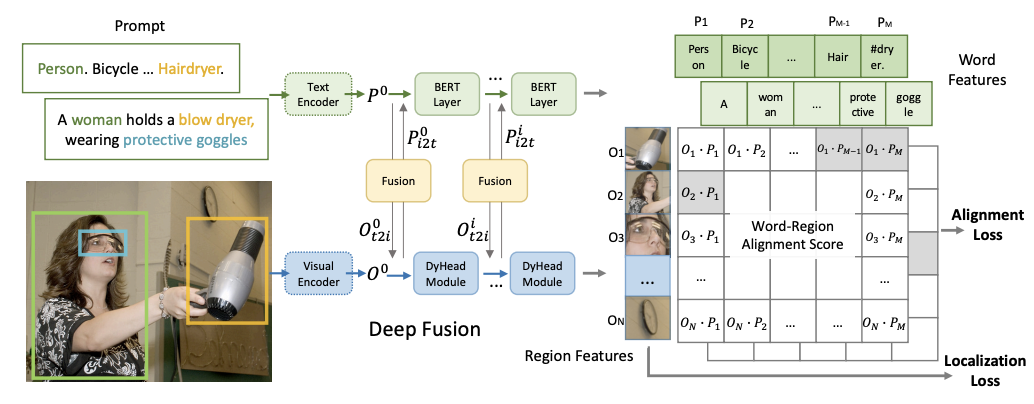
GLIP aligns specific regions in an image with their corresponding text prompts
Combining the Pieces: Grounded Detection + Segmentation
Now that we have a) method to segment a given image and b) assign given text descriptions to specific sub-regions in an image, why don’t we combine these 2 to get segmentation + open set recognition capabilities for arbitrary images? This is exactly what Grounded-SAM does: the Grounded-DINO model produces bounding boxes for user-provided text descriptions, and these boxes are used as prompts to SAM to output segmentation masks in a zero-shot manner (Alternatively, we could have also performed a per-pixel correlation maximization between the text and image embeddings to directly get an open-set semantic map, which is what LSeg does). Furthermore, we can train these models with text order aware hard negative examples to improve their compositional understanding, bringing us closer to fulfilling all the criteria we needed our VFM to fulfill at the beginning of this post.

Grounded SAM combines open set object detection from Grouding DINO with SAM's segmentation capabilities
Concluding Remarks
This post does not cover generative capabilities of Vision based Foundation Models - including but not limited to image generation, inpainting, image editing and visual instruction tuning. Learning from and making sense of videos is another area where a vision foundation model should excel at - along with being inherently multimodal, videos also have a temporal aspect that needs to be accounted for. It is also important to note that the aforementioned combination of methods is one way of thinking about VFM. The field is moving fast, with many other techniques such as SemanticSAM, LAVIS, SAM-CLIP, SEEM etc that have come up with their own criteria, frameworks and benchmark tasks for VFM capabilities.