How to think with images
- Introduction
- Understanding vs. Generation in Vision
- Unifying Vision – Are We There Yet?
- Vision Without Words: Do Models Need Language?
- The Many Paths of Vision
Introduction
“Think with images” - this is the promise of recent models like o3 from OpenAI, which can integrate images directly into their chain-of-thought, even zooming in or rotating an image as part of the reasoning process. The fact that it took this long to release such a capability hints that doing a reliable visual search in an image remains surprisingly hard. Why? In text, we deal with concepts already encoded into words, but an image is raw pixels – a dense, noisy form of signal. Two pictures of the same size might carry wildly different amounts of information. One could be a simple photo of a single object, while another could be a chaotic “Where’s Waldo?” scene filled with tiny characters. Humans tackle this by zooming in and out, scanning for relevant clues. AI models, however, often struggle to localize and count things in crowded images. In fact, studies show that even state-of-the-art vision-language models (VLMs) strrugle at tasks trivial for humans – like deciding if two shapes overlap or counting simple objects. Their suboptimal performance on such visual acuity tests suggests that current AIs sometimes “see” like a myopic person, missing fine details. All this underscores a core challenge: visual understanding is high-bandwidth and context-dependent. An image doesn’t highlight the important bits for you – an AI has to figure that out on its own, potentially by thinking with images in a more human-like way.

Understanding vs. Generation in Vision
For a long time, computer vision followed two parallel paths. One focused on understanding images – identifying what’s in an image and where it is. The other path tried having models generate pictures from scratch. These two paths developed largely separately, but recently they are converging. To appreciate how we got here, let’s briefly recap some key advances in image generative models:
• Variational Autoencoders (VAEs): VAEs were among the first modern generative models that learned to compress images into a latent code and then reconstruct them. They optimized a probabilistic lower bound, but often produced blurry outputs. A big issue was posterior collapse – the decoder would sometimes become too powerful and learn to ignore the latent representation. The result? The latent space carried little meaningful information.
• VQ-VAE (Vector Quantized VAE): To fix that, VQ-VAEs discretize the latent space. The encoder outputs indices into a learned codebook of prototypical vectors instead of continuous codes. This simple change prevents the continuous optimization issues that caused posterior collapse. Essentially, the model can’t cheat by blurring everything – it must choose discrete “tokens” to represent an image. Selecting the prototype vector for each smaller component in the latent space grid instead of the entire grid ensures diversity in generation - there is a combinatorial explosion in terms of getting the generated image. Paired with an autoregressive prior over these tokens, VQ-VAE greatly improved generation quality. It preserved important details better and enabled models that generated not just images but also audio and video with impressive fidelity.
• VQ-GAN: Building on VQ-VAE, the VQ-GAN introduced adversarial training and perceptual losses to sharpen the results. Rather than just minimizing pixel-wise differences (which can still produce fuzziness), a patch-based discriminator judges the reconstructed image quality. This pushes the generator to produce crisper, more realistic details. In short, VQ-GAN modified the VAE approach to match some of the realism that pure GANs (Generative Adversarial Networks) were known for, but without the instability of training a separate generator/discriminator from scratch for every new dataset.
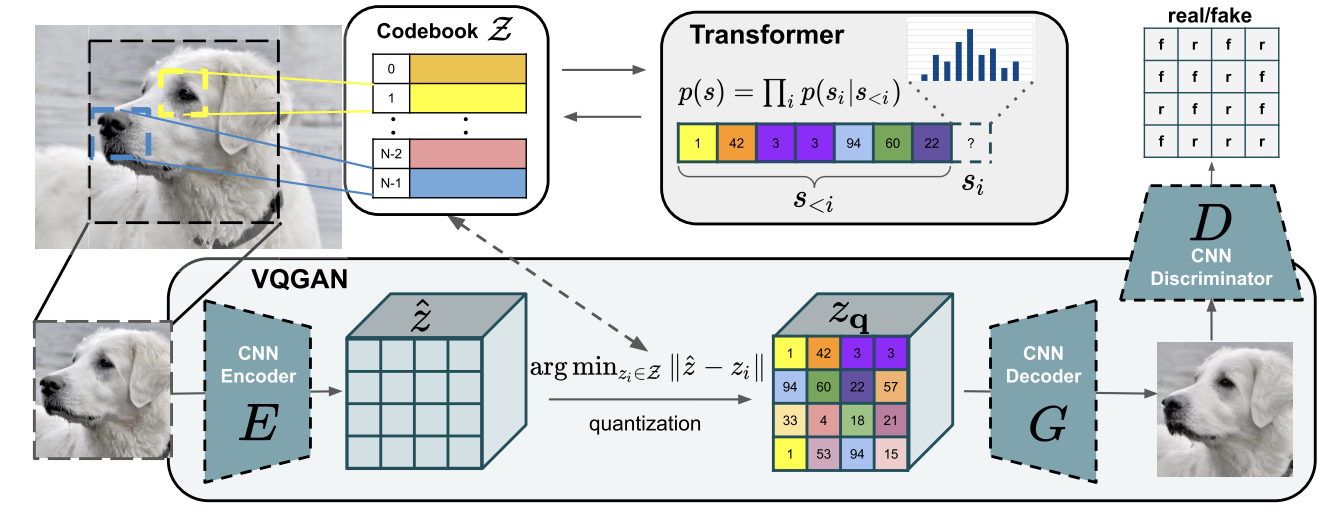
VQ-GAN architecture - combine the efficiency of convolutional approaches with the expressiveness of transformers
• Diffusion Models: The next revolution came from a very different approach. Diffusion models generate images by iteratively denoising random noise, effectively learning to reverse a gradual noising process. During training, the model sees images with various levels of noise and learns to predict the noise added. Generation starts from pure noise and the model refines it step by step, “imagining” the picture as it erases noise. This process is slower than one-shot generation but astonishingly effective at producing high-quality, diverse images. Diffusion models don’t suffer mode-collapse and tend to capture fine details well. They have quickly become the state-of-the-art for text-to-image generation, as seen in tools like Stable Diffusion and DALL-E. One downside: working in pixel space is expensive – diffusion needed hundreds of steps on high-resolution images, which was a hurdle for speed.
• Latent Diffusion & Flow Models: To speed things up, ideas were combined. Latent diffusion compresses images with an autoencoder first (often a VAE) and then runs the diffusion process in the smaller latent space. This two-step training (first train a VAE, then a diffusion model on its codes) preserves fidelity while cutting computation dramatically – some works have reported ~2.7× faster generation and 3× faster training by working with latent space. Meanwhile, normalizing flows offered another strategy: learn a single invertible transformation from noise to image (and vice versa) that gives exact likelihoods. Flows can be seen as a continuous generalization of the diffusion idea – in fact, you can view the diffusion reverse process as solving an ODE akin to a flow. In practice, flows achieved decent results but struggled to match diffusion in image realism, and they often required lots of parameters to capture complex image distributions. Still, flows introduced useful theoretical tools and insights for generative modeling.
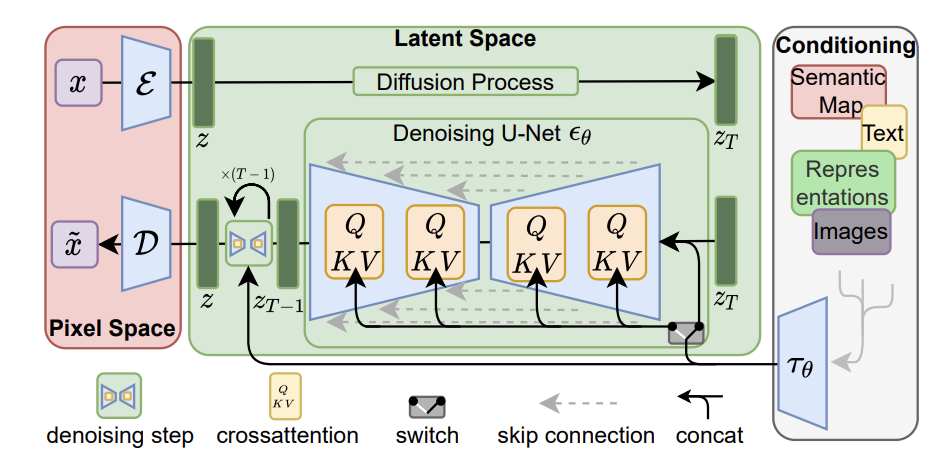
In latent diffusion, the model encodes input images into a latent space, where a diffusion process adds noise and a denoising U-Net reverses it step by step. Conditioning inputs (e.g., text, semantic maps, images) are injected via cross-attention to guide generation
Each of these innovations – from VQ-VAE to diffusion – was driven by a quest for better computational efficiency, training stability, and output quality. For example, latent VAE models avoided the posterior collapse problem of vanilla VAEs by using discrete codes, and latent diffusion avoided the huge expense of pixel-level modeling by working on compressed representations. Most modern diffusion systems still train the image compressor (e.g. VAE) and the diffusion model separately. Recently, however, researchers have asked: why not train them end-to-end? A new training recipe called REPA-E does exactly that – it adds a “representation alignment” loss that lets the diffusion model and VAE learn together without one dominating the other. The result is faster training (a 45× speedup over the vanilla approach in one report!) and improved generative performance. In fact, end-to-end diffusion training with REPA-E not only sped things up ~17× relative to prior tuned methods, it even produced a better VAE the latent space became more structured, leading to a new state-of-the-art FID (image quality score) on ImageNet. It’s a great reminder that joint training can unlock capabilities that separate training misses.
• Contrastive Language-Image Pretraining : While generative models were evolving, another thread of research tackled the understanding side of vision by directly linking images with language. A landmark was OpenAI’s CLIP . CLIP learned by simply predicting which caption goes with which image, across hundreds of millions of random image-text pairs from the web. This contrastive learning forces an image encoder and a text encoder to meet in the middle – to produce embeddings that match for a true pair and differ for a mismatched pair. CLIP’s latent space turned out to be remarkably semantically rich. All sorts of concepts (from objects to styles to famous faces) are encoded in a way that text and image descriptions align. This means we can do zero-shot classification: to recognize dogs vs. cats, we don’t fine-tune on thousands of labeled photos – we just embed the image and the text “a photo of a dog” (or “…cat”) and see which is closer in CLIP space.
• SigLIP : CLIP wasn’t alone for long. Variations soon appeared, such as Google’s SigLIP (“Sigmoid” CLIP), which tweaked the training loss. Instead of comparing all image-text pairs globally in a big softmax, SigLIP uses a pairwise sigmoid loss. This removes the need for extremely large batch sizes and negative sampling across the whole batch. In practice, SigLIP was found to outperform CLIP under smaller batch training regimes while still reaching similar performance at scale. It’s basically a more efficient way to train an image-text bi-encoder, addressing some engineering headaches of CLIP (which ideally needed huge batches like 32k samples or more).
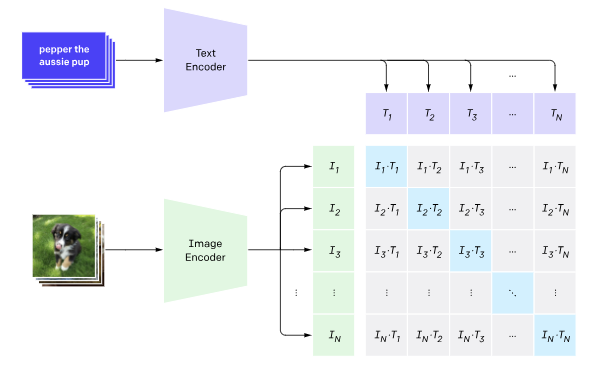
CLIP demonstrated that large scale contrastive learning on text-image pairs can yield robust semantic representations
• BLIP : Another line of work, BLIP (Bootstrapping Language-Image Pretraining), took a slightly different approach. Instead of just learning “this image matches this caption”, BLIP models also learned to generate captions and even perform VQA (visual question answering) in a unified framework. The original BLIP introduced a captioning model that could filter out noisy data – it bootstrapped itself by generating captions and then training on those refined pairs. The result is a system that can accept an image and a question and then output a fluent answer, or produce a description, etc. Unlike CLIP’s single embedding space, BLIP has a generative head: it doesn’t just tell you which text is closest; it can actually speak about the image. This makes BLIP more effective on tasks requiring nuanced understanding and reasoning (e.g. writing a caption that truly reflects an image’s details or answering questions that require combining observations) – things that a pure embedding model like CLIP might miss. In essence, CLIP vs. BLIP highlights a difference in representation: CLIP’s embeddings are like conceptual keywords (great for retrieval and recognition), whereas BLIP’s model (with its language generation capability) carries more of the context and syntax, making it better at composing sentences about an image.
Unifying Vision – Are We There Yet?
Having separate specialized models – one to generate images, another to caption them, another to answer questions – is not very elegant. The dream is a single AI that can see and generate, answer and ask, all in one system. How to get there? Two broad strategies have emerged: unify by fusion (build one model that does everything) or unify by coupling (connect a vision-understanding model to a vision-generating model).
On the “fusion” front, one trend is to treat everything as a sequence of tokens and train one big transformer to predict the next token – whether that token comes from text or from an image. Can we extend the success of autoregressive transformers (like GPT) to vision, by converting images into a language-like form? LVM (Large Vision Model) is one such example. It represents images (and even videos, plus optional annotations like segmentation masks) as sequences of discrete tokens – essentially turning pixels into a stream of “visual words”. Then it trains a transformer to predict the next token on a massive corpus of these visual sentences (420 billion tokens). Remarkably, this purely vision-trained model can handle many tasks by simply being prompted with the right visual context. For instance, to classify an image, you might feed the model an image of a dog followed by a special “[CLASS]” token and see what label token it predicts next – akin to asking it, in visual terms, “what is this?” The authors report that with the right “visual prompts,” a single LVM can do segmentation, object detection, depth prediction, and more. This hints that a sufficiently large sequence model could learn a kind of general visual reasoning, parallel to how LLMs exhibit general language reasoning. The upside of this approach is unification through format – everything becomes a token sequence, so in theory one model handles all. The downside is it may require enormous data and compute, and it’s not yet clear if such models truly reason or just cleverly memorize visual patterns.

Large Vision Model - Each row represents a prompt composed of a sequence of images interleaved with annotations, ending in a query. Model predicts the final column.
Another attempt at unification is more hybrid: use one model to cover vision understanding and generation by bolting together the strengths of each. An example from 2025 is the MetaQueries approach. Instead of training one monolithic model from scratch, MetaQueries proposes a neat interface to connect an autoregressive multimodal LLM with a diffusion image generator. It introduces a set of learned query vectors that take the rich latent features from the language model (which has “understood” the user’s request and visual context) and feed them into the diffusion model’s decoder to produce an image. MetaQueries can train this connection with relatively standard image-caption pairs and diffusion objectives. Crucially, you don’t need to fine-tune the large language model – it can be frozen. This avoids degrading the language model’s knowledge, while still leveraging it to guide image generation. Early results showed that this combo could perform “knowledge-augmented” generation – for instance, ask the system to draw an image of a historical event, and it can use the language model’s knowledge to get details right. And because the interface is learned, it outperforms simpler methods like prompt engineering.
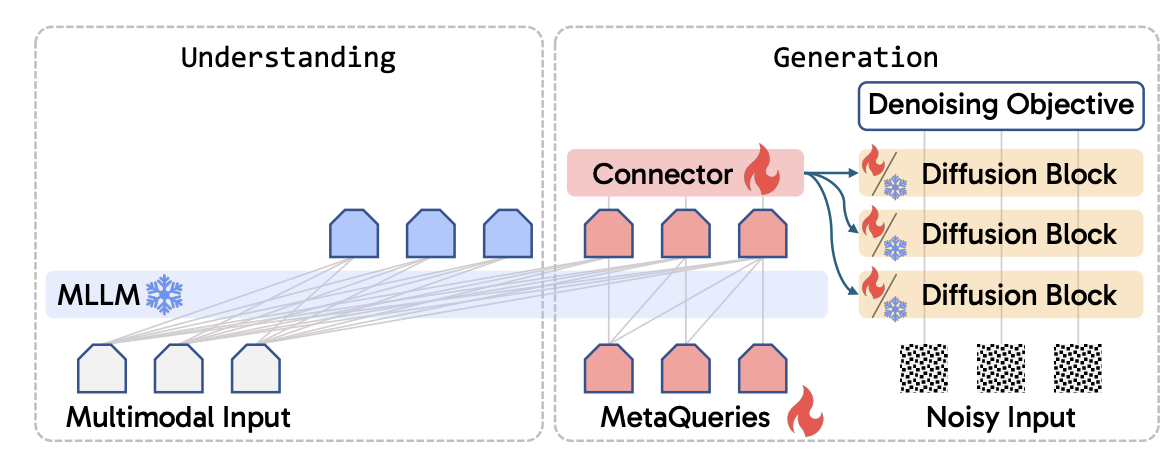
Metaqueries are a set of learnable queries that connect the MLLM’s latents to the diffusion decoder
Between the extremes of one-model-for-everything and two-models-coupled, there’s a lot of room. Some methods try to merge models but still keep modularity inside. For example, the SEED-X system aims for a “unified multi-granularity” vision model – one that can both comprehend and generate, and do so at various levels of detail. SEED-X emphasizes handling arbitrarily sized images (which is vital for practical applications) and multi-scale generation. Under the hood, it still uses separate modules (it builds on a previous SEED-LLaMA architecture), but the integration is tight enough that, from the user’s perspective, you have one coherent model that will both interpret your input images and also produce new images on demand.
Another intriguing approach is to actually let the model write and execute code or symbolic plans as part of solving a visual task. This doesn’t unify generation and understanding in a single network, but it provides a unified framework to handle complex tasks by breaking them down. VisProg (Visual Programming) is an archetypical example. It uses a LLM to compose a Python program from a high-level instruction, using a library of vision functions as building blocks. The program might say, “detect all people in the image, then find the one wearing red, then describe what they are doing,” implemented by calling pretrained detectors, segmenters, etc. VisProg then executes this program step by step on the image, and even returns a visual rationale – basically a stitched image showing what each step did. The good part: VisProg required no additional training for those complex multi-step tasks. It leveraged GPT-3’s in-context learning to generate the right programs from just a few examples. This neuro-symbolic approach was demonstrated on tasks like compositional VQA, image editing by instructions, and reasoning about image pairs. Similarly, ViperGPT showed that an LLM can generate Python code to answer visual queries by gluing together classic vision models. Given a question and an image, ViperGPT defines some primitive operations (like get_text(img) for OCR, or find_objects(img, “cat”) for detection) and then asks GPT-4 to write a little program using those operations to find the answer . The code is executed to provide an answer along with an interpretable chain-of-thought. Impressively, these code-based methods achieved state-of-the-art on certain benchmarks that stump end-to-end models(for example, counting objects or requiring logic). The conclusion here is that unification doesn’t have to mean one big model; it can also mean unifying vision and language through a shared reasoning procedure (like a generated program), which plays to the strengths of both symbolic logic and deep learning perception.

VISPROG is a modular neuro-symbolic system that uses in-context learning to generate and execute interpretable visual reasoning programs from natural language instructions
Pure end-to-end learning is still alive and pushing boundaries. A line of work referenced as V* (or “V-star”) takes a stance that visual search should be a first-class citizen in multimodal models. The model proposes that an AI should be able to iteratively search within an image – effectively doing its own zoom and enhance–guided by the user’s query. It introduces an auxiliary mechanism that crops or resamples the image in a loop: first the model looks at the whole image and identifies a region of interest related to the question, then it “zooms in” on that region for a closer look, possibly repeating this to hone in further. By integrating this procedure, it was able to answer fine-detail questions on ultra-high-resolution images, where a single pass would have been insufficient. To evaluate such capabilities, they also created VBench, a benchmark explicitly focused on high-resolution visual search and reasoning. VBench includes tasks like attribute recognition in a large scene (e.g. find the small blue car in a 4K image and tell if its headlights are on) and spatial reasoning that requires examining details. Early results show that many multimodal models struggle on VBench, especially if they cannot effectively handle very large images. Approaches like these offer one broad theme: incorporate a search strategy into the model’s architecture (in this case, a transformer-based vision encoder that can dynamically switch between a broad overview and a focused view. Another broad theme we see across these efforts is the heavy use of transformers everywhere – even diffusion models, which started with CNN-based U-Nets, are now often built as transformers or at least use transformer blocks for mixing in text prompts and temporal embeddings. The transformer’s ability to flexibly attend to different parts of its input (be it an image or a sequence of image patches) is a unifying thread whether we’re doing generation (text-conditioned diffusion for example) or doing understanding (vision transformers attending to image patches, or multimodal transformers attending across image tokens and text tokens). In short, the modern trend is to generalize the “language model” idea to images, either by tokenizing images or by letting models move back and forth between visual and textual modes via attention.
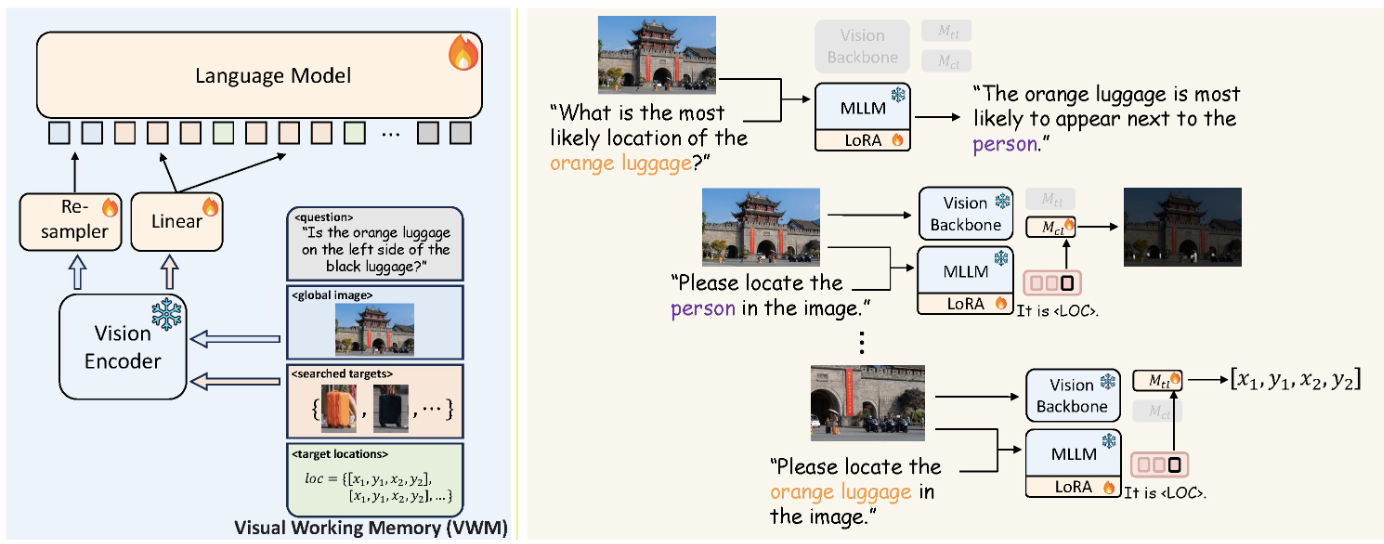
V* enables referential and spatial reasoning by integrating visual working memory into a language model. Visual features from a frozen encoder are re-sampled and injected into a language model, enabling it to predict object relations, identify referents, and localize targets via bounding boxes
Apart from architectural choices, works such as MM1 discuss the importance of dataset composition and training procedure in multimodal training. MM1 shows that careful mixing of image-caption, interleaved image-text, and text-only data, along with factors such as image resolution and the choice of image encoder are crucial for achieving state-of-the-art performance on multiple benchmarks.
Vision Without Words: Do Models Need Language?
Interestingly, a recent debate in the community is how far we can get in vision tasks without relying on language at all. Humans, after all, understood a lot about sight long before we had language. Is language supervision (captions, labels) a crutch that we can potentially do without for training powerful vision models? The LVM work we discussed earlier is one attempt – it deliberately omits any linguistic data. Another examples are IDEFICS and Cambrian-1 which, while not completely language-free, place heavy emphasis on self-supervised visual training. Cambrian-1, in particular, is described as a “vision-centric” multimodal model. Instead of plugging in the biggest language model and hoping it will compensate for a mediocre vision backbone, Cambrian-1 experiments with strong vision backbones and novel connectors. It uses multiple vision encoders: a CLIPViT for robust object recognition, a SigLIP model for fine-grained details, an OpenCLIP-ConvNeXt for high-resolution features, and a DINOv2 self-supervised encoder for holistic scene understanding. These diverse “views” of the image are then fused by a Spatial Vision Aggregator (SVA) module. The SVA uses learnable query tokens that attend to all the encoder features, effectively learning to pick and merge information from each (with a bit of spatial bias so that each query focuses on a localized region). And it doesn’t just do this once – the aggregated tokens are fed into the language model and the process is repeated across multiple layers, meaning the model can refine its visual understanding as it generates an answer.
One finding from this work is that before, purely self-supervised vision features (like DINOv2) lagged behind CLIP’s text-supervised features on many tasks. But if you close the data scale gap and fine-tune with enough multimodal data, that gap narrows significantly. In fact, by instruction-tuning with ~5 million examples and allowing the vision backbone to update (instead of keeping it frozen), they brought DINO’s performance much closer to CLIP’s. This suggests that language isn’t a magical requirement for learning good visual representations – it’s just one useful source of training signal. If you can provide equally rich signal via other means (e.g. multi-task training, extremely large image datasets, or pretext tasks), a model might learn “visual common sense” nearly as well as one taught with image-caption pairs. Work like IDEFICS similarly shows that starting from a strong self-supervised ViT and then aligning it to language can yield multimodal models that are competitive with those trained on huge captioned sets.
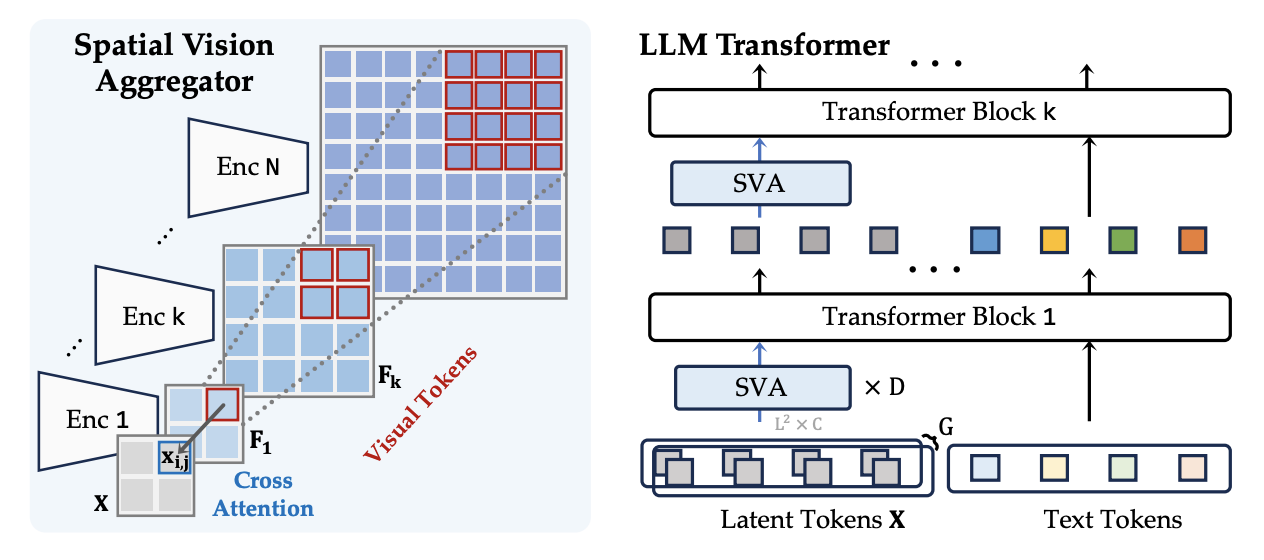
Spatial Vision Aggregator used in Cambrian-1 is a dynamic, spatially-aware connector that fuses vision features with LLMs while minimizing token usage
The Many Paths of Vision
When we talk about “vision,” it’s actually a whole family of tasks. There’s recognition (what is this?), detection (where is it?), segmentation (which pixels belong to it?), captioning (put it in words), visual reasoning (answer a question about it), generation (imagine a new image), and more. Historically, the field broke these out into separate benchmarks and leaderboards – ImageNet for classification, COCO for detection, VOC for segmentation, VQA for question answering, etc. Each task had specialized models and techniques. But with the rise of large foundation models, we’re starting to see individual systems tackle many of these tasks at once, and that needs rethinking on how we evaluate them. Researchers have begun constructing holistic benchmarks to probe what these Vision-Language Models (VLMs) can really do. For example, the ARO benchmark tests fine-grained understanding by checking if a model knows which attributes belong to which object, how objects relate, and the correct order of things in an image. On ARO, it was found that even strong models often behave like a “bag of words”, ignoring relationships – e.g. they might detect “yellow” and “car” in an image but not realize the yellow object is actually the boat next to the car, not the car itself. Another provocative evaluation, VLMs are Blind gave models a series of simple vision tests (count some circles, find a small shape, read a tiny letter) and showed that models that do great on complicated benchmarks can fail basic eyesight exams. At the time of this work’s release, on seven low-level vision tasks, four cutting-edge VLMs averaged only ~58% accuracy, whereas humans are basically 100%.
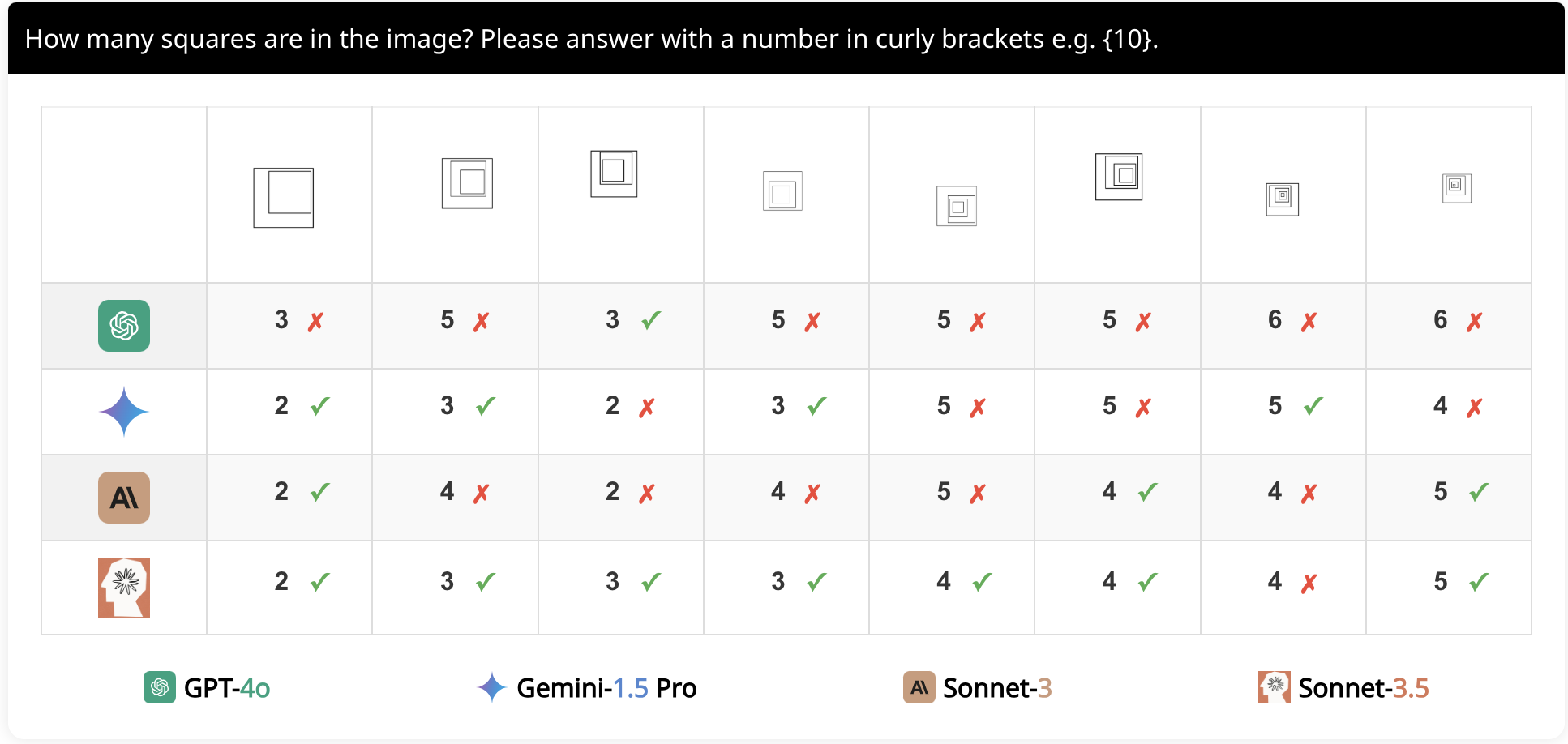
"VLMs are Blind" - this work shows that multimodal models can struggle with low-level vision tasks that are easy to humans
The good news is that with each iteration, these models are improving on the blind spots. There’s active research on enhancing visual acuity – for instance, a recent method called LVLM-Count uses a divide-and-conquer approach to improve counting by having the model explicitly count in parts of the image and sum up. And the high-res focus methods (like V*, zoom- based prompting, etc.) are closing the gap for localization in large images. We also see specialized components being used as tools: for example, Meta’s Segment Anything Model (SAM) can be used as a plug-in to give an LLM precise segmentation when needed, or tools like OCR modules can be called for reading small text. In the long run, though, these might become internalized skills. AI researcher Ross Girshick gave a keynote in CVPR 2024 where he called tasks like object detection “fake tasks” – not because they’re useless, but because they exist as intermediate stepping stones. If your real goal is to answer a question about an image, you might not need to deliberately output a set of boxes first (as a human, you don’t list all bounding boxes before answering a question about an image either). With end-to-end learning and enough data, the model might learn to do “implicit detection” or segmentation as part of its reasoning, without being asked to output those explicitly. In other words, tomorrow’s vision models might treat what we now call detection or segmentation like how a compiler treats parsing – an invisible internal process that feeds into understanding, rather than a final product.
So, how to think with images? The emerging consensus is: by combining perception with cognition in an intertwined loop. The future vision systems will not just be pattern recognizers nor just image generators; they’ll be problem solvers that use images as flexible information. They might generate hypothetical images as part of their thought process (imagine asking an AI, “What would this room look like painted blue?” and it mentally conjures that image before answering). They might inspect an image the way we inspect a diagram – focusing on relevant parts, recalling related knowledge (“I see a stethoscope, this is likely a doctor’s office”), and even sketching or annotating on the image to work through a problem. All the threads we discussed – contrastive representation learning, generative modeling, the fusion of modalities, the use of search and programs – are converging toward AI that can see deeply and imagine freely. As ML researchers, it’s an exciting time because the old boundaries are falling. The journey isn’t finished – there are still plenty of “Waldo” moments where AI struggles to find what’s obvious to us. But with each innovation, we are teaching our models new ways to think with images, inching closer to a fluid intelligence that perceives and creates visual information as effortlessly as we do with words.